ICS Chapter I
CSAPP NOTE CHAP 1
Chap 1 计算机系统概述#
计算机的发展历程#
了解即可,略去。
计算机系统的基本组成和功能#
计算机是一种能自动对数字化信息进行算术和逻辑运算的高速处理装置。
基本功能#
- 数据处理
- 加、减、乘、除
- 与、或、非
- 数据存储
- 程序
- 数据
- 存储部件:非易失存储器和快速存储器
- 数据传送
硬件组成#
- 冯诺依曼结构
- 硬件组成
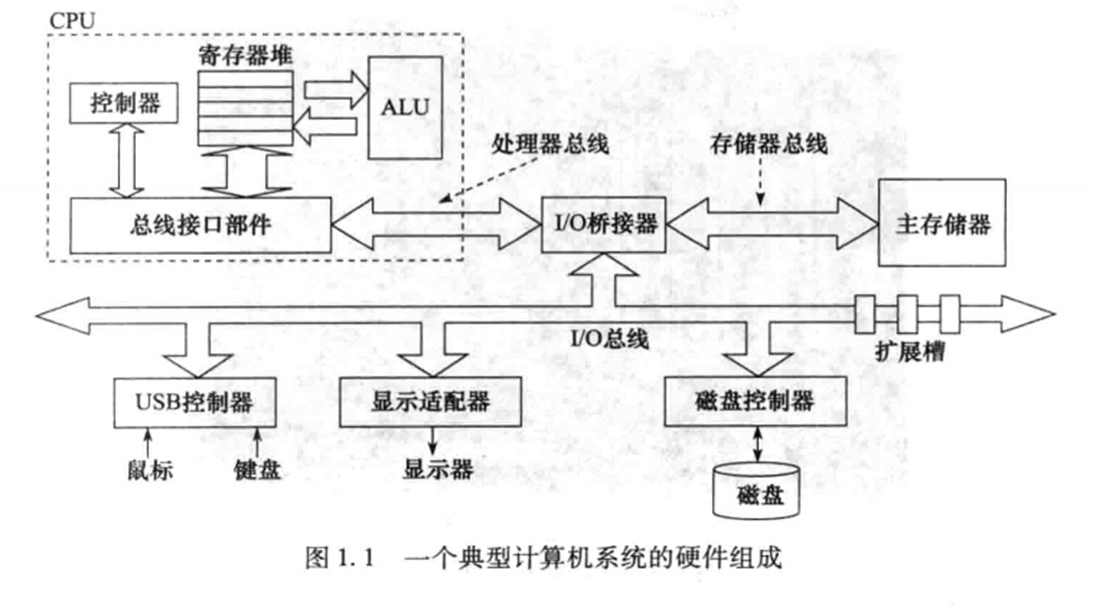
这里还有简化版:

另外谈到 CPU 和 主存,这两个是非常重要的


CPU 结构#
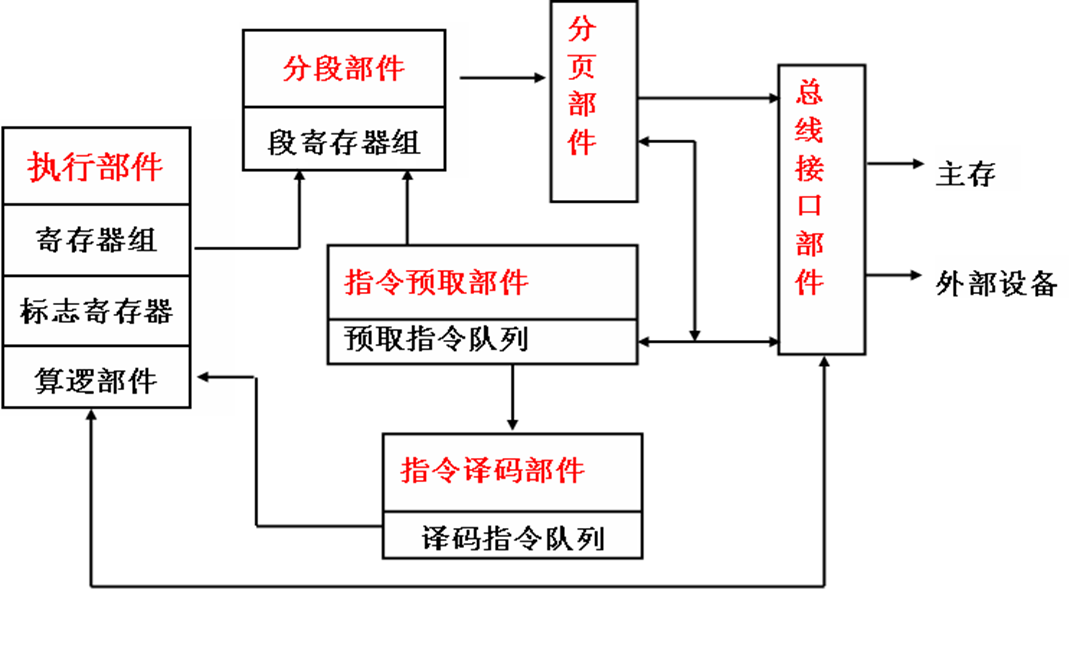
- 总线接口部件:是 CPU 与整个计算机系统之间的高速接口
- 功能:接受所有的总线操作请求,并按优先权进行选择,最大限度的利用本身的资源为这些请求服务。
- 执行部件:寄存器组、标志寄存器、算逻部件、控制部件等组成
- 功能:从译码指令队列中取出指令并且执行
寄存器组#
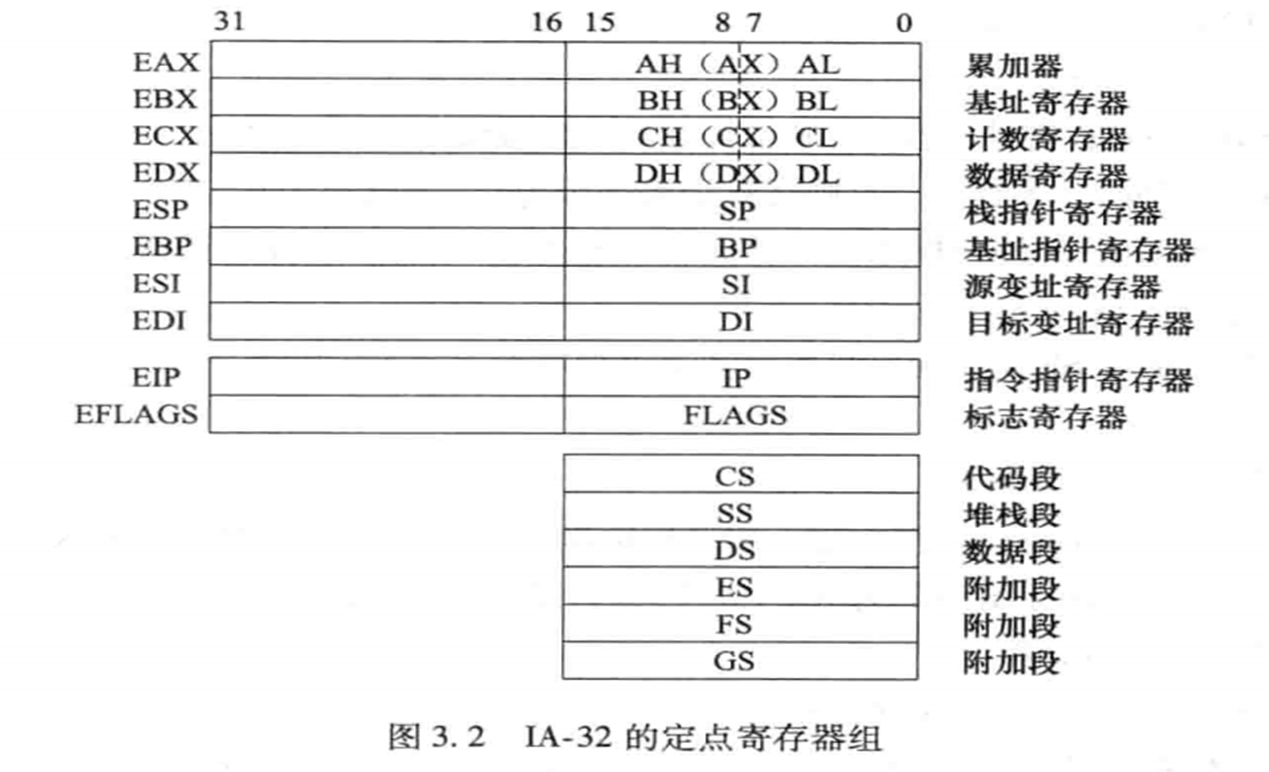
-
数据寄存器组:
eaxebxecxedx- 用来保存操作数、元素按结果或作指示器、变址寄存器等
-
指示器变址寄存器组:
esiediespebp- 作用:用来存放操作数的偏移地址、用作指示器或变址寄存器
- ESI 源变址寄存器 字符串指令源操作数的指示器
- EDI 目的变址寄存器 字符串指令目的操作数的指示器
- ESP 堆栈指示器(栈顶、低地址)
- EBP 基址寄存器(栈底、高地址)
-
标志寄存器 保存一条指令执行后,CPU所处状态的信息
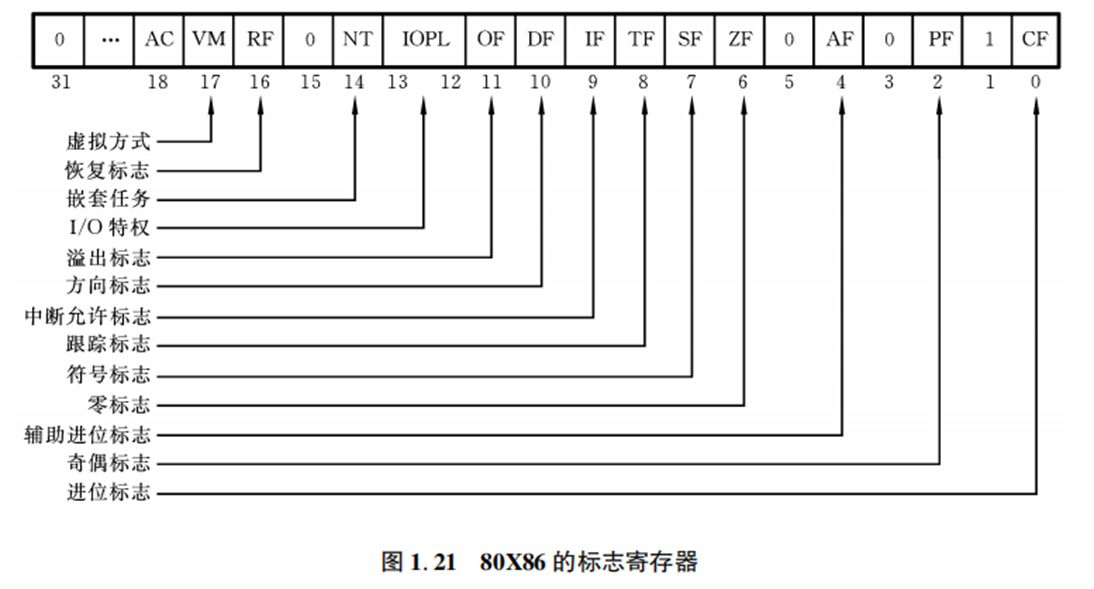
其中分为 条件标志 和 控制标志
- 条件标志(常用!)
- OF 溢出 Overflow
- SF 符号 Signed
- ZF 零标志 Zero
- CF 进位标志 Carry
- 控制标志(这门课不用)
- DF 方向标志
- IF 中断允许标志
- TF 陷阱标志(单步执行)
-
指令预取部件和指令译码部件
- 指令预取部件:通过总线接口部件,把将要执行的指令从主存中取出,送入指令排队机构中排队。
- 指令译码部件:从指令预取部件中读出指令并译码,在送入译码指令队列排队供执行部件使用。
- 指令指示器EIP:总是保存下一条将要被 CPU 执行的指令的偏移地址,其值为该指令到所在段首址的字节距离。
-
分段部件和分页部件
- 使用分段部件和分页部件实现虚拟存储空间映射到物理存储空间
- 程序员使用二维地址 “段地址:段内偏移地址” (即先根据代码、数据、堆栈分段,调用的时候再在对应段内使用偏移地址寻找)
- 分段部件把二维地址变成一维线性地址,然后分页部件再把这些地址转换到存储器的实际物理地址
- 代码段寄存器 CS
- 堆栈段寄存器 SS
- 数据段寄存器 DS
- 附加段寄存器 ES
- 附加段寄存器 FS
- 附加段寄存器 GS
软件开发和执行过程概述#
从源程序到执行程序#
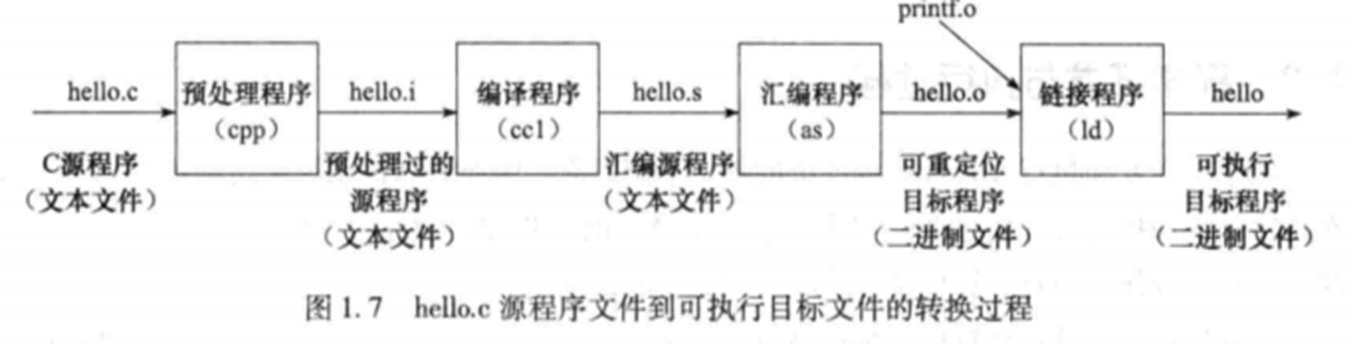
- 源程序:文本文件,用户编写。
- *.c/.cpp/.asm
- 目标程序:二进制文件,机器可识别,但不能执行
- *.o( *.obj)
- 可执行程序:二进制文件,机器可执行
- */ *.exe
- 编译器:将源程序转为目标程序
- 链接器:将一个或多个目标程序链接生成可执行程序
可执行程序的启动和执行#

- 从硬盘上将可执行程序的文件加载到内存中
- 将 EIP 指向程序第一条指令
- CPU 开始执行程序
程序中每条指令的执行#
机器指令的一般形式为 操作码 地址码
机器指令完成开头说的某一个基本操作。
每条指令的执行过程:
- 从内存中读取该指令
- 对指令进行译码
- 若为内存操作数,从内存中取操作数
- 对操作数进行运算
- 保存运算结果。若为内存操作数,保存结果到内存中
一个汇编语言程序的例子#
.386
;堆栈段
STACK SEGMENT USE16 STACK ;段名和组合类型
DB 200 DUP(0) ; 堆栈的大小为200个字节
STACK ENDS
;数据段
DATA SEGMENT USE16 ;段为16位段
SUM DW ? ;SUM为字变量,初值不定
DATA ENDS
;代码段
CODE SEGMENT USE16
ASSUME CS:CODE, SS:STACK, DS:DATA, ES:DATA
START: MOV AX, DATA
MOV DS, AX;数据段首址送DS
MOV CX, 50;循环计数器置初值
MOV AX, 0 ;累加器置初值
MOV BX, 1 ;1→BX
NEXT:ADD AX, BX;(AX)+(BX)→AX
INC BX
INC BX ;(BX)+2→BX
DEC CX ;(CX)-1→CX
JNE NEXT ;(CX)≠0转NEXT
MOV SUM, AX ;(CX)=0累加结果→SUM
MOV AH, 4CH
INT 21H ;返回DOS
CODE ENDS
END START ;源程序结束语句。程序运行时,启动地址为START在该例子中,一共定义了三个段:堆栈段、数据段和代码段
汇编语句的一般格式:[NAME] 操作符 [操作数/ADDRESS] [COMMENT]
- 操作符可分为 3 类:指令、伪指令、宏
- 操作数也分为 3 类:数值操作数、寄存器操作数、内存操作数
汇编过程及 Turbo debugger 的使用略过,因为这门课程使用的平台基本上是 Linux + gcc + gdb
计算机系统的层次结构#
计算机抽象层次的转换#
- 计算机系统是一个层次化的系统,上层提供抽象接口,下层实现细节。
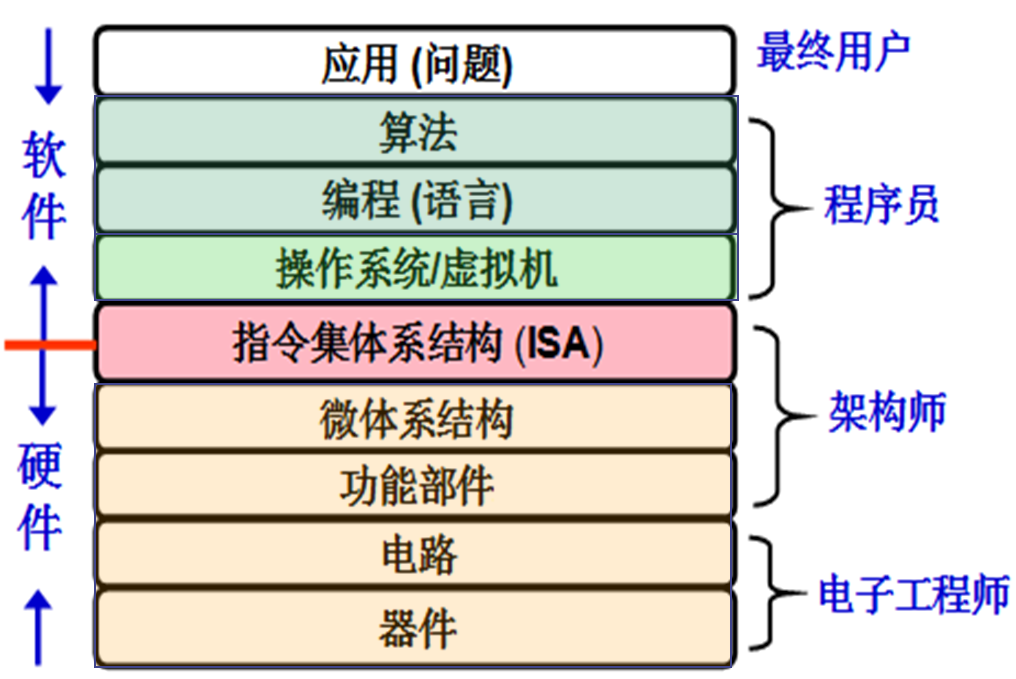
-
指令集体系结构 ISA
ISA 是硬件和软件的交界,是计算机系统的核心部分,ISA 的内容包括
- 指令集
- 操作数
- I/O
- 中断
- 机器状态切换
- 存储保护等
-
微体系结构
相同的 ISA,可以有不同的微体系结构实现,比如 Intel/AMD 的多种不同实现
- 微体系结构由功能部件组成
- 由逻辑电路实现

- ISA 是硬件和软件的交界,是计算机系统的核心部分
计算机系统性能评价(本节最重要的一部分)#
计算机系统性能定义#
计算机系统性能由以下两个指标决定:
- 吞吐率
- 响应时间
- 执行时间
- 等待时间
计算机系统性能测试#
- 用程序的执行时间测试计算机性能 (了解即可)
- CPU 时间
- 用户 CPU 时间
- 系统 CPU 时间
- 其他时间
- 磁盘访问
- 存储其访问
- 输入输出
- 操作系统额外开销
- CPU 时间
此处老师推荐了一篇 CSDN 上的文章 CPU 的时间观 ↗

- CPU 性能和系统性能不等价,主要考虑 CPU 性能,即用户 CPU 时间
- 时钟周期/频率
- CPI 指令所需时钟周期数
- 一条指令 CPI
- 平均 CPI
即有以下几个等式:
其中 (3) 式中 F_i 为第 i 种指令所占比例,CPI_i 为第 i 中指令的 CPI
时钟周期、指令条数、CPI 三者相互制约,优化用户 CPU 时间时,需要综合考虑。
例如,指令条数少了那么对应的时钟周期会变长,时钟周期变短可能会导致 CPI 变大
例子 1
程序P在机器A上运行需10 s, 机器A的时钟频率为400MHz。
现在要设计一台机器B,希望该程序在B上运行只需6 s。由于机器B时钟频率的提高导致了其CPI的增加,使得程序P在机器B上运行时,总时钟周期数是在机器A上的1.2倍。机器B的时钟频率达到A的多少倍才能满足设计要求?
解答
用户CPU时间 = 平均CPI * 程序总指令条数 * 时钟周期 = 总时钟周期数 / 时钟频率
CPU时间A = 总时钟周期数A / 时钟频率A
CPU时间B = 总时钟周期数B / 时钟频率B
总时钟周期数B = 1.2 * 总时钟周期数A,CPU时间A = 10s,CPU时间B = 6s
∴ 时钟频率B = 总时钟周期数B / CPU时间B
= 1.2 * 总时钟周期数A / CPU时间B
= 1.2 * CPU时间A * 时钟频率A / CPU时间B
= 1.2 * 10 * 400M / 6 = 800M(Hz)例子 2
机器M上有三类指令A、B、C,其CPI分别为1、2、4。程序P在M上被编译为目标代码P1和P2,P1含A、B、C三类指令条数为8、2、2,P2含A、B、C三类指令条数为2、5、3。
P1和P2,哪个总指令条数少?哪个执行速度快?平均CPI分别为多少?
解答
| P1 | P2 | |
|---|---|---|
| 总指令条数 | 8+2+2=12 | 2+5+3=10 |
| 总时钟周期数 | 8*1+2*2+2*4=20 | 2*1+5*2+3*4=24 |
| 平均CPI | 20/12=1.67 | 24/10=2.4 |
∴ P2的总指令条数少,P1的执行速度快。
-
早期使用每秒完成指令条数 MIPS 衡量计算机性能
MIPS 为每秒执行多少百万条记录。
数值上有以下式子:
例子
机器M上有四类指令A、B、C、D,其CPI分别为1、2、2、2。程序P在M上编译,优化前的四类代码为43%、21%、12%、24%;优化后A类指令条数减少50%,其他指令条数不变。假设机器M频率为50MHz。优化前后程序的CPI分别为多少?优化前后程序的MIPS各是多少?
解答
| 优化前 | 优化后 | |
|---|---|---|
| 总指令条数 | 100 | 43/2 + 21 + 12 + 24 = 78.5 |
| 总时钟周期数 | 43\1+21\2+12\2+24\2=157 | 43/2\1+21\2+12\2+24\2=135.5 |
| 平均CPI | 1.57 | 135.5/78.5=1.73 |
| MIPS | 50M/1.57=31.8 | 50M/1.73=28.9 |
注:用 MIPS 对不同的机器进行性能比较,有可能不准确或不客观。例如,Intel 喜欢把一些复杂的操作写成一条指令。
-
浮点相关性能参数(了解即可)
浮点操作速度单位—— GFLOPS、TFLOPS、PFLOPS
浮点运算实际上包括了所有涉及小数的运算,在某些应用软件中常常出现,比整数运算更费时间。
现今大部分的处理器中都有浮点运算器。
每秒浮点运算次数所量测的实际上就是浮点运算器的执行速度。
最常用来测量每秒浮点运算次数的基准程序(benchmark)之一,就是Linpack。
MFLOPS——每秒一佰万(=10^6)次的浮点运算
GFLOPS——每秒拾亿(=10^9)次的浮点运算
TFLOPS——每秒万亿(=10^12)次的浮点运算
PFLOPS——每秒千万亿(=10^15)次的浮点运算
EFLOPS——每秒百亿亿(=10^18)次的浮点运算
-
Benchmark 相关内容
这里已经是基本没用的东西了,直接略去。